나만의 Stable Diffusion 서비스 배포
Stable Diffusion은 stability.ai에서 출시한 text-to-image model 오픈소스 입니다. Stable Diffusion은 자연어 프롬프트로 부터 단 몇초만에 창의적인 예술품을 생성할 수 있습니다.
Stable Diffusion을 왜 Online으로 불러오는 것인가?
제한적인 local 컴퓨터에서 Stable Diffusion 모델이 좋은 품질의 이미지를 생성하기 위해 오랜 시간이 필요합니다. 모델을 온라인 클라우드 서비스에서 실행하게 된다면 사실상 제한없는 컴퓨터 자원을 사용할 수 있게 되어 높은 품질의 결과물을 보다 빠르게 얻을 수 있습니다. Microservice 단위로 모델을 호스팅하면 ML 모델을 온라인에서 실행해야하는 복잡한 절차 없이 모델 성능을 레버리지 할 수 있고 보다 창의적인 애플리케이션을 제작할 수 있습니다.
Stable Diffusion을 EC2에서 배포
Stable Diffusion 모델을 온라인으로 호스팅하는 한가지 방법은 BentoML 과 AWS의 EC2를 활용하는 것입니다. BentoML은 기계 학습 서비스를 대규모로 구축, 배포 및 운영할 수 있는 오픈소스 플랫폼입니다. 이 글에서는 BentoML을 사용하여 제품에 즉시 사용할 수 있는 Stable Diffusion 서비스를 생성하고 이를 AWS EC2에 배포합니다. 아래는 이 글의 절차들을 수행하면 얻을 수 있는 결과물 입니다.
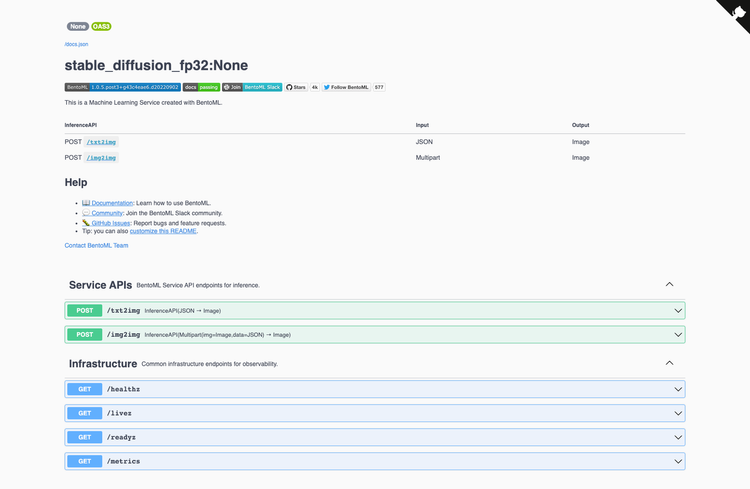
RESTful OpenAPI 서비스 /txt2img (text to image) 와 /img2img(image + text to image) 앤드포인트들을 갖고 있는 Swagger 유저 인터페이스

/txt2img 엔드포인트를 활용하여 텍스트 프롬프트로 생성된 예시 이미지

/img2img 엔드포인트를 활용하여 이미지 및 텍스트 프롬프트로 생성된 예시 이미지
Prerequisites
코드와 샘플들은 이 글(https://github.com/bentoml/stable-diffusion-bentoml)에서 찾을 수 있습니다.
환경 및 Stable Diffusion Model 준비하기
저장소 복제 및 의존성 설치
git clone https://github.com/bentoml/stable-diffusion-bentoml.git && cd stable-diffusion-bentoml
python3 -m venv venv && . venv/bin/activate
pip install -U pip
pip install -r requirements.txt
Stable Diffusion model을 선택하여 다운로드하세요. Single Precision(FP32)는 10GB 이상의 VRAM이 있는 CPU 또는 GPU에 적합합니다. Half Precision(FP16)는 10GB VRAM 미만의 GPU에 적합합니다.
Single Precision (FP32)
cd fp32/
curl https://s3.us-west-2.amazonaws.com/bentoml.com/stable_diffusion_bentoml/sd_model_v1_4.tgz | tar zxf - -C models/
Half Precision (FP16)
cd fp16/
curl https://s3.us-west-2.amazonaws.com/bentoml.com/stable_diffusion_bentoml/sd_model_v1_4_fp16.tgz | tar zxf - -C models/
Stable Diffusion Betno 구축
모델을 RESTful API로써 serve하기 위해 우리는 BentoML service를 만들것입니다. 다음 예제는 예측을 위한 single precision 모델과 service.py 모듈을 사용하여 비즈니스 로직으로 서비스를 결합합니다. @svc.api 데코레이션을 활용하여 함수를 APIs로 노출시킬 수 있습니다. 뿐만아니라 input과 output의 type을 지정해줄 수 있습니다. 예를 들어, txt2img 앤드포인트는 JSON 을 입력을 받아 Image 출력을 반환하는 반면 img2img 앤드포인트는 Image 와 JSON 을 입력으로 받아 출력으로 Image 를 반환합니다.
@svc.api(input=JSON(), output=Image())
def txt2img(input_data):
return stable_diffusion_runner.txt2img.run(input_data)
@svc.api(input=Multipart(img=Image(), data=JSON()), output=Image())
def img2img(img, data):
return stable_diffusion_runner.img2img.run(img, data)
inference logic의 핵심은 StableDiffusionRunnable 에 정의되어 있습니다. runnable은 모델에서 txt2img_pipe 및 img2img_pipe 메서드를 호출하고 필요한 arguments를 전달하는 역할을 합니다. custom runner는 API에서 모델 inference logic을 실행하기 위해 StableDiffusionRunnable 에서 인스턴스화 됩니다.
stable_diffusion_runner = bentoml.Runner(StableDiffusionRunnable, name='stable_diffusion_runner', max_batch_size=10)
다음 명령어을 실행하여 테스트용 BentoML 서비스를 시작합니다. 로컬의 CPU에서 Stable Diffusion 모델 추론을 실행하는 것은 매우 느립니다. 각 요청을 처리하는데 약 5분이 소요됩니다. 다음 섹션에서는 GPU가 있는 머신에서 서비스를 실행하여 추론 속도를 가속화 하는 방법을 탐구할 것입니다.
BENTO_CONFIG=configuration.yaml bentoml serve service:svc --production
Curl the text-to-image /txt2imgendpoint.
curl -X POST http://127.0.0.1:3000/txt2img -H 'Content-Type: application/json' -d "{\"prompt\":\"View of a cyberpunk city\"}" --output output.jpg
Curl the image-to-image /img2img endpoint.
curl -X POST http://127.0.0.1:3000/img2img -H 'Content-Type: multipart/form-data' -F img="@input.jpg" -F data="{\"prompt\":\"View of a cyberpunk city\"}" --output output.jpg
필요 파일 및 종속성은 bentoml.yaml 파일에 정의되어 있습니다.
service: "service.py:svc"
include:
- "service.py"
- "requirements.txt"
- "models/v1_4"
- "configuration.yaml"
python:
packages:
- torch
- transformers
- diffusers
- ftfy
docker:
distro: debian
cuda_version: "11.6.2"
env:
BENTOML_CONFIG: "src/configuration.yaml"
아래 명령어로 Bento를 만들 수 있습니다. Bento는 BentoML 서비스의 배포 형식입니다. 서비스 실행에 필요한 파일과 설정들을 포함하는 독립적 아카이브 입니다.
bentoml build
🎉Stable Diffusion bento가 구축되었습니다. 만약 bento를 성공적으로 만들 수 없었다면 걱정하지 마세요 아래 명령어를 이용하여 사전 제작된 bento를 다운로드 할 수 있습니다.
Download Single Precision (FP32) Stable Diffusion Bento
curl -O https://s3.us-west-2.amazonaws.com/bentoml.com/stable_diffusion_bentoml/sd_fp32.bento && bentoml import ./sd_fp32.bento
Download Half Precision (FP16) Stable Diffusion Bento
curl -O https://s3.us-west-2.amazonaws.com/bentoml.com/stable_diffusion_bentoml/sd_fp16.bento && bentoml import ./sd_fp16.bento
EC2에서 Stable Diffusion Bento 배포
우리는 bentoctl을 이용하여 bento를 EC2에 배포할 것입니다. bentoctl는 당신의 bento들을 Terraform로 클라우드 플랫폼에 배포하는 것을 돕습니다.
bentoctl operator install aws-ec2
배포를 위한 설정들이 deployment_config.yaml 파일에 구성되어 있습니다. 해당 사양들을 자유롭게 업데이트 해주세요. 기본 설정으로 us-west-1 region에 Deep Learning AMI GPU PyTorch 1.12.0 (Ubuntu 20.04) AMI가 있는 g4dn.xlarge 인스턴스에 Bento가 배포하도록 구성되어 있습니다.
api_version: v1
name: stable-diffusion-demo
operator:
name: aws-ec2
template: terraform
spec:
region: us-west-1
instance_type: g4dn.2xlarge
# points to Deep Learning AMI GPU PyTorch 1.12.0 (Ubuntu 20.04) 20220913 AMI
ami_id: ami-0a85a3a3fb34b3c7f
enable_gpus: true
Terraform 파일 생성
bentoctl generate -f deployment_config.yaml
Docker 이미지를 만들고 AWS ECR로 push 합니다. 이미지 업로드는 대역폭에 따라 시간이 오래 걸릴 수 있습니다.
bentoctl build -b stable_diffusion_fp32:latest
AWS EC2에 bento를 배포하기 위해 Terraform 파일을 등록합니다. EC2 콘솔에서 브라우저를 퍼블릭 IP 주소로 공개하여 Swagger UI에 접근이 가능합니다.
bentoctl apply -f deployment_config.yaml
마지막으로 Stable Diffusion BentoML 서비스가 더 이상 필요없다면 배포를 삭제합니다.
bentoctl destroy -f deployment_config.yaml
결론
이 글에서 저희는 BentoML을 사용하여 Stable Diffusion을 위한 production-ready 서비스를 구축하고 AWS EC2에 배포했습니다. AWS EC2에 서비스를 배포함으로써 더 강력한 하드웨어에서 Stable Diffusion 모델을 짧은 지연시간으로 이미지를 생성하고 단일 시스템 이상으로 확장할 수 있었습니다. 이 글을 재미있게 읽었다면 github의 Bentoml project에 ⭐ 와 slack community에서 마음에 맞는 분들을 만나보시길 바랍니다.
Reference
해당 자료는 BentoML Blog를 번역한 자료 입니다. 원본 자료