Weights & Biases Meet-up 후기
Weights & Biases에서 주최한 Meet-up에 참석하여 공유된 주요 내용과 함께 개인적으로 감명 깊었던 점, 들었던 생각들을 분리하여 기록하고 공유합니다.
 Meetup 포스터
Meetup 포스터
1. 신뢰할 수 있는 AI를 위한 평가: LLM 평가와 벤치마크 트렌드
주요 내용 요약
첫 번째 세션에서는 AI 씬에서 벤치마크가 어떻게 정복되어 왔는지, 그리고 최근 트렌드는 어떻게 변화하고 있는지 공유되었습니다.
- 벤치마크 정복 속도: 과거 컴퓨터 비전 분야(MNIST, ImageNet 등) 벤치마크 정복에 약 10년이 걸렸지만, ‘Attention is All you need’ 논문 이후 트랜스포머와 대량 데이터를 활용한 LLM 씬에서는 주요 벤치마크가 1~2년 만에 정복되는 빠른 추세를 보입니다.
- 벤치마크 트렌드 변화:
- 정적 → 동적: 과거 고정된 Test dataset 기반(정적) 평가에서, 최근에는 특정 시나리오 환경에서의 동작 여부/소요 시간 기반(동적) 평가가 주를 이루고 있습니다. (특히, 최근 각광받는 Agentic system 성능 향상을 위한 벤치마크들)
- 범용 → 특정 도메인: 과거 General Task 목적 설계에서, 최근에는 특정 도메인 특화 벤치마크들이 공개되고 있습니다.
- 평가 방법의 진화:
- Human Eval: 전통적인 사람이 직접 평가하는 방식입니다.
- Automatic Eval: 시스템 자동 평가 방식으로 발전 중입니다.
- Rule-based: 예시로 Github Issue를 LLM이 보고 해결 PR을 만들어 Unit test 통과 여부로 자동 평가 가능. (코딩 영역은 이런 workflow가 잘 설계되어 발전이 빠름)
- LLM as Judge: LLM을 평가자로 활용. 효율성과 나쁘지 않은 성능으로 많이 사용되지만 명확한 한계점 존재.
- 최신 소식 (OpenAI PaperBench): AI 에이전트의 연구 재현 능력을 평가하는 PaperBench 논문 공개. AI 모델의 자율적 연구 능력 발전 및 안전 개발 확인 목적.
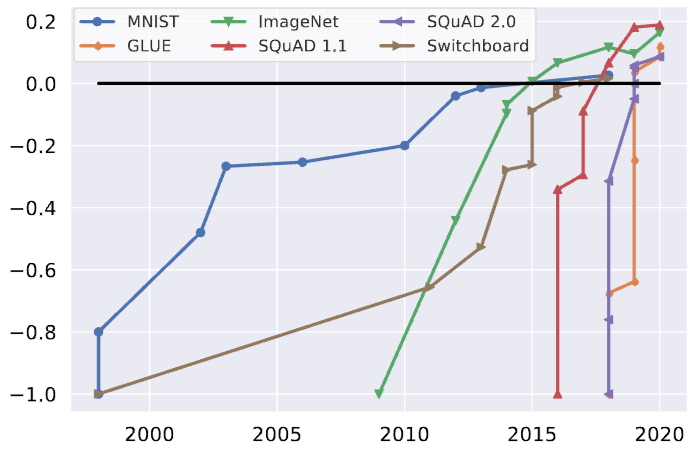 [LLM 벤치마크 정복 속도 비교 그래프]
[LLM 벤치마크 정복 속도 비교 그래프]
개인적인 생각 및 질문
세션 이후, LLM 기반으로 만들어진 서비스 자체를 평가하는 벤치마크나 방법론에 대해 개인적으로 질문했습니다. 답변에 따르면, 관련 연구는 최근 시작되어 참고할 만한 연구가 많지 않으며, 당분간은 세션에서 이야기한 유닛 테스트 방식 등이 주를 이룰 것으로 보인다는 의견을 들었습니다. LLM 모델 자체의 성능 평가를 넘어, 실제 사용자에게 제공되는 서비스로서의 가치를 어떻게 측정하고 검증할 것인가가 앞으로 중요한 과제가 될 것 같습니다.
2. 회의록 자동 생성 서비스 개발기 (롯데)
주요 내용 요약
두 번째 세션에서는 롯데에서 사용하는 회의록 자동 생성 서비스 개발의 전반적인 내용을 소개했습니다.
- 서비스 워크플로우:
- 발화자 분리: 음성 데이터 임베딩 → 발화자 수에 맞게 군집화(Clustering)하여 구분.
- STT: Whisper 모델 활용 음성 → 텍스트 변환.
- 텍스트 정제: 변환된 텍스트를 LLM으로 회의록 형태 가공.
- 개발 과정 핵심:
- 데이터셋 확보: 개발 초기 AI-Hub 데이터 활용했으나 품질 문제로 선별 사용, 결국 자체 데이터셋 제작 진행. (데이터셋이 가장 주요했음을 강조)
- 인프라/모델 최적화: H100 2장 환경에서 8B LLM 모델 활용, Whisper Large 모델 학습 후 경량화 작업으로 서비스 환경에 최적화.
개인적인 생각
역시 실제 서비스를 개발할 때는 양질의, 그리고 목적에 맞는 데이터셋 확보가 핵심이라는 점을 다시 한번 느꼈습니다. AI-Hub 데이터도 선별 작업이 필요했고 결국 자체 제작까지 진행했다는 경험 공유가 인상 깊었습니다. 또한 H100 2장과 최적화된 모델을 사용하는 등, 실제 서비스 환경에 맞는 충분한 인프라 확보와 모델 최적화 노력도 뒷받침되어야 함을 확인할 수 있었습니다.
3. 금융 분야에서의 LLM 기반 예측 (LG)
주요 내용 요약
마지막 세션은 LG에서 진행한 연구 및 개발로, 금융 분야 예측(Forecasting)에 LLM을 사용하는 과정 중 얻은 인사이트 공유가 주요 내용이었습니다.
- 데이터 활용 인사이트:
- 수치 데이터만으로 좋은 성능이 나올 때 비정형 데이터를 혼합하면 큰 차이가 없거나 오히려 성능 저하 가능성.
- 반면, 수치 데이터만으로 성능이 좋지 않을 때 비정형 데이터를 활용하면 성능이 크게 오르는 경우가 많았음.
- LLM 활용 방안:
- Interpreter (설명 가능성): 예측/결정의 근거 설명 (별도 Fine-tuning 필요).
- Data Augmentation: 합성 데이터 생성.
- Information Retriever: 문맥적 지식 추출.
- Interpreter(설명 가능성)의 중요성: 금융 분야에서는 의사결정 승인을 위해 충분한 근거(Causal Information) 제시가 필수적이므로, Interpreter 역할에 중점을 두고 Fine-tuning(Instruction tune, Agent tuning 등)을 진행했다고 함.
- 실제 적용 사례 (ETF ‘LQAI’): 해당 인사이트를 활용하여 Forecasting competition에서 좋은 성적을 얻고, 이를 기반으로 뉴욕 증시 ETF(LQAI) 상품화. (보유 주식 포트폴리오 리밸런싱에 개발 서비스 활용)
- 전통 모델 한계 및 LLM 강점:
- 전통 ML은 팩터(Factor) 중요도가 동적으로 변화하는 점이 어려움.
- LLM은 이런 동적 변화 포착 및 데이터가 적은 신생 기업 평가(View score + Explainability 동시 제공)에 강점.
개인적인 생각 및 공감
금융 분야에서 ‘설명 가능성(Explainability)’ 확보를 위해 Interpreter 역할에 집중하고 별도의 Fine-tuning을 진행했다는 점이 특히 흥미로웠습니다. 단순히 예측 정확도를 넘어 ‘왜’ 그런 결과가 나왔는지 설명하는 것이 실제 의사결정과 승인 과정에 얼마나 중요한지를 보여주는 사례였습니다. (LG의 자체 LLM인 Exaone과 충분한 인프라가 있기에 가능한 접근 방식이라는 생각에 조금 부럽기도 했습니다.)
전통 ML 모델이 금융 예측에서 어려움을 겪는 이유로 ‘Factor Feature Importance가 Dynamic하게 변화한다’는 점을 지적한 부분은 매우 공감되는 인사이트였고, 미처 깊게 생각하지 못했던 부분이었습니다.
또한, 예측(Forecasting)과 동시에 해석(Interprete)이 가능해진다면, 서비스 운영 중에도 실시간으로 알고리즘의 유효성을 평가하고 개선하는 데 매우 유용할 것 같다는 생각이 들었습니다.
마지막으로 연사님이 세션을 종료하며 정리한 “문제 해결에서 ‘어떻게(How)’는 중요하지 않다. ‘목표(Goal)’가 구체적이고 ‘평가(Evaluation)’가 명확한 것이 중요하다.” 라는 메시지에 크게 공감했습니다. 최신 기술 자체에 매몰되기보다, 풀고자 하는 문제의 본질과 명확한 목표 설정, 그리고 이를 검증할 수 있는 평가 기준 마련에 더 집중해야 한다는 다짐을 하게 되었습니다. 많은 기술자들이 흔히 저지르는 실수이기도 하죠.
이번 Meet-up을 통해 LLM 평가의 최신 동향부터 실제 산업 적용 사례까지 폭넓은 인사이트를 얻을 수 있었습니다. 특히 각 세션에서 강조된 ‘명확한 목표 설정’과 ‘신뢰할 수 있는 평가’의 중요성은 앞으로 AI 기술을 다루는 데 있어 계속 되새겨야 할 부분인 것 같습니다.