MLops is all you need?
What is MLOps??
⚠️ 필자의 개인적인 의견이 많은 내용으로 유의바람
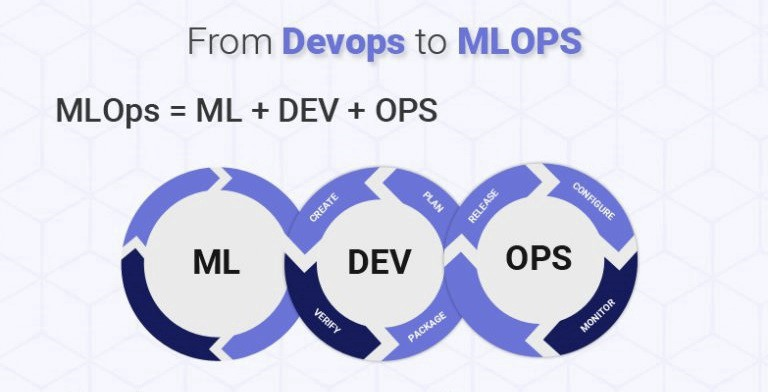 MLOps = ML + Dev + Ops
MLOps = ML + Dev + Ops
많은 사람들이 MLops에 대한 이해를 ML + Devops라고 정의한다. 이보다 명확한 설명이 Wikipedia에 있다.
MLOps or ML Ops is a set of practices that aims to deploy and maintain machine learning models in production reliably and efficiently.
해석하자면 MLOps는 머신 러닝 모델을 안정적이고 효율적으로 배치하고 유지하는 것을 목표로 하는 일련의 관행이다. 여기서 중요하게 생각해야하는 것은 안정적, 효율적, 배치, 유지 이다.
Why to study MLOps??
ML competition
필자는 kaggle과 dacon, 머신러닝 경진대회를 통해서 모델링과 ML문제들을 풀었다.


경진대회를 통해 여러 공부들을 많이 했지만 “real world에서 발생하는 문제들을 내가 직접 해결할 수 있을까??”
에 대해서 고민하였을 때 스스로에게 부족함을 많이 느꼈다. 그 이유는 경진대회에서는 이미 준비가 되어 있는 것이 많다. 그 예로 두 가지가 있는데
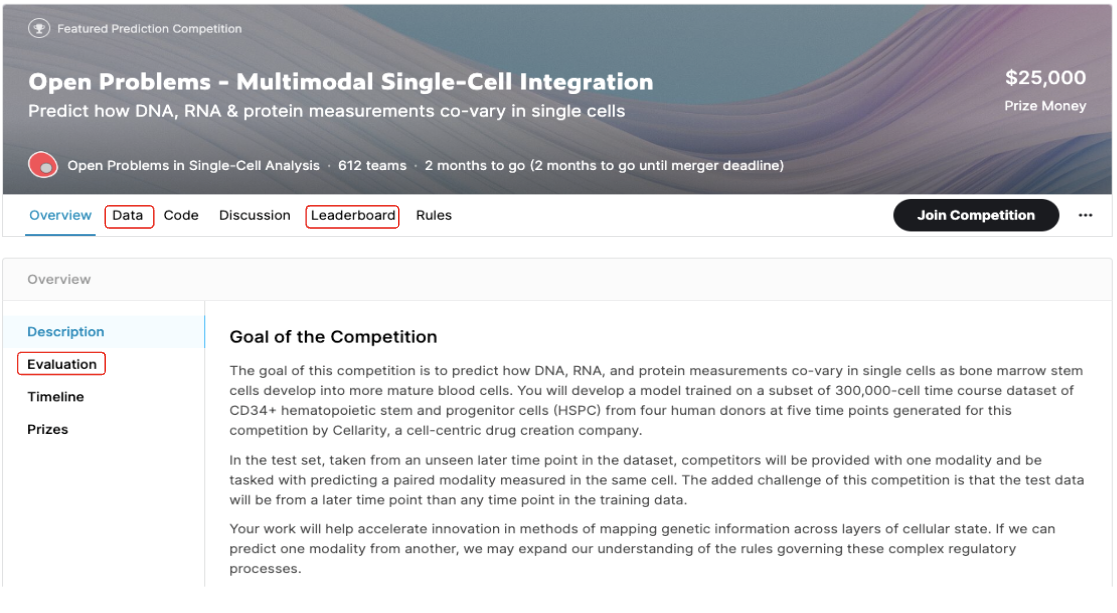
- 데이터셋 (물론 train / test 데이터 셋을 분류해서 제공해줌)
- 정의되어 있는 metrics
Test 데이터 셋과 metrics는 프로젝트의 이정표와 같다. 제공해야하는 서비스의 방향성과 설정한 Test 데이터 셋과 metrics가 설정된다면 프로젝트 기간과 resource들을 낭비가 일어날 수 밖에 없다.
ML 서비스 개발을 위한 절차
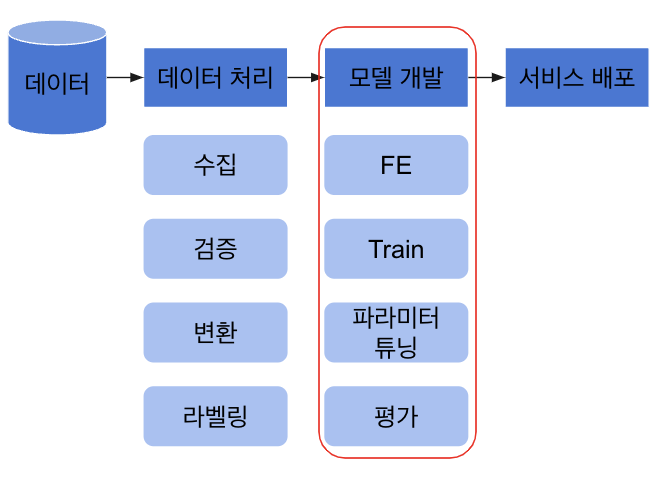
ML 서비스가 나오기 위해서는 복잡한 절차를 통해서 나오는 것이지만 간단하게 표현하자면 데이터 수집 → 데이터 처리 → 모델 개발 → 서비스 배포 절차로 진행된다.(기획, 서비스 관리 등 복잡하고 어려운 것들이 많다.) 많은 ML competition 플랫폼들과 많은 ML 개발자, 학생들도 모델 개발에 많은 집중을 한다. 하지만 이 부분은 ML 서비스를 만들기 위해 극히 일부분에 해당한다.
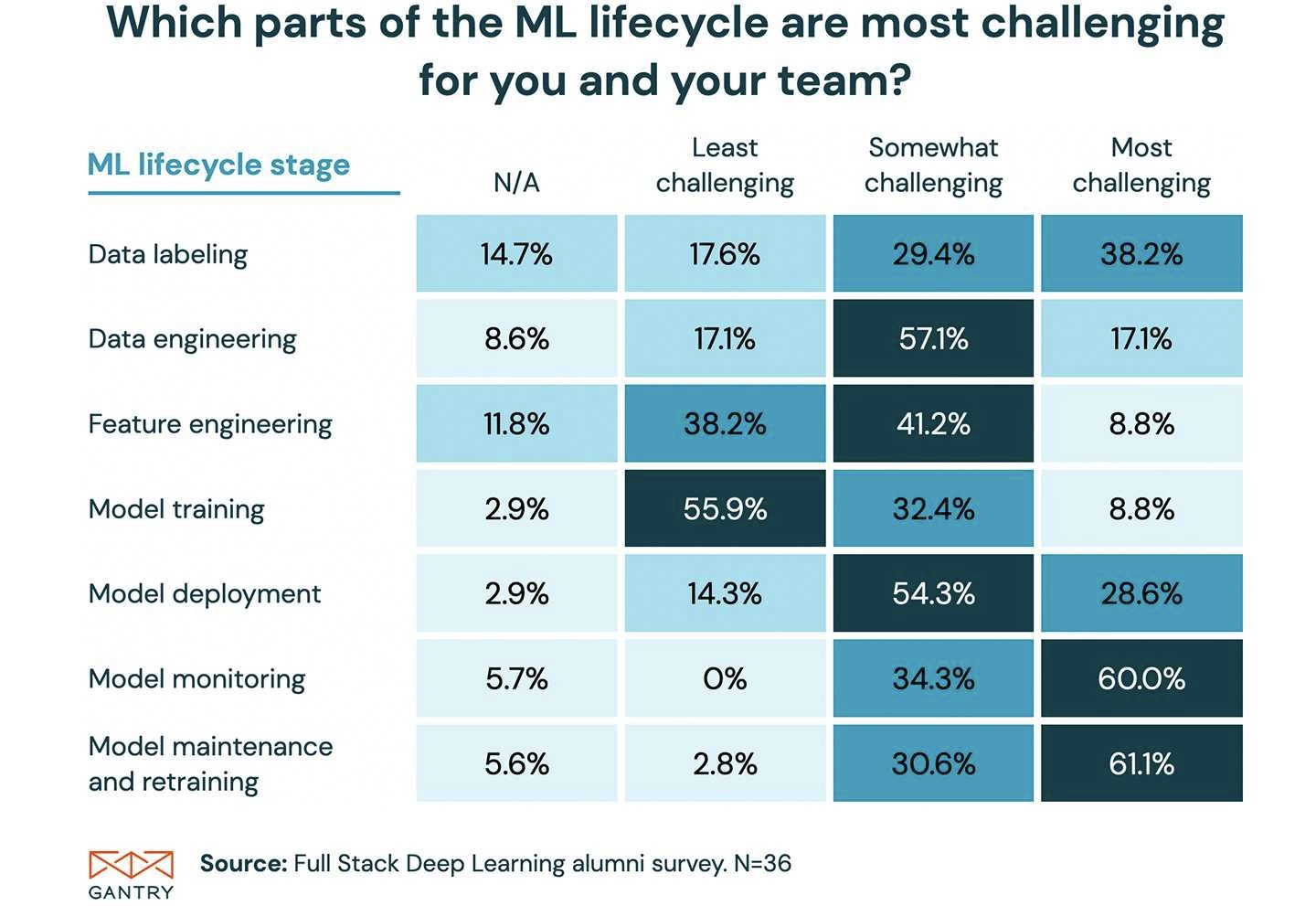
위는 트위터를 통해 UC Berkely 졸업생 대상으로 ML service를 만들때 어렵다고 생각하는 Task가 무엇인지 설문한 것이다. 졸업생들은 Model training은 어렵지 않게 진행할 수 있다고 답변하였으며 나머지에 대해서는 대부분 어렵다고 답변하였다. 특히 Model monitoring, Model maintenance and retraing은 매우 어렵다고 답변하고 있다. 그 이유를 생각해보자면 해당 Task로 구성되어 있는 수업이 흔하지 않다는 것이 가장 큰 이유일 것 같다.
(이중 설문 결과가 특이한 Task가 Data labeling이다. 다른 Task에 비해 결과의 분산량이 크다. 이는 설문자 별로 생각하는 Data labeling이 서로 달라 발생하는 결과인 것 같다. 예를 들자면 단순한 노동으로 생각하는 설문자도 있으며 라벨링 또한 어렵고 복잡한 Task라고 평가하는 설문자들도 있는 것으로 생각된다.)
How to build MLops
Google에서의 ML service
(google) 2015**](/assets/images/MLOps-is-all-you-need/Untitled%207.png)
Hidden Technical Debt in Machine Learning Systems(google) 2015
구글에서는 ML service를 만들때 ML code는 전체 시스템에서 가장 작은 부분을 차지한다고 평가하고 있다. 심지어 구글에서 발표한 논문 제목을 머신러닝을 숨겨진 부체라고 표현하고 있다. 논문 내용에서는 Machine learning system은 데이터 종속적인 점을 중심으로 다양한 문제점들을 기술하고 있다. 그럴만한게 머신러닝 모델은 데이터로 부터 생성되는 부산물로써 좋지 않은 데이터에서는 좋지 않는 머신러닝 모델이 나오는 것은 당연하다.
Data dependencies system
Machine learning으로 서비스를 제공하기 이전과 이후를 비교한다면 아래와 같다.
- ML system이 있기 이전에는 어떤 것이 필요했을까? (Software 1.0)
- computing
- code + algorithm
- ML system 도입을 위해 필요한 것은? (Software 2.0)
- computing
- code + algorithm = model
- Data
Software 1.0과 Software 2.0의 차이는 Data라고 볼 수 있다. 물론 Software 1.0에서도 Data를 활용하였지만 Software 2.0에서 데이터를 활용하여 모델을 만들거나 알고리즘을 만들만큼 중요한 요소로 적용되지 않았을 것으로 예상된다. 이에 Software2.0으로 넘어오면서 부족한 요소일 것이며 중요한 요소가 될 것으로 예상된다.
real-world ML service 데이터의 기여도
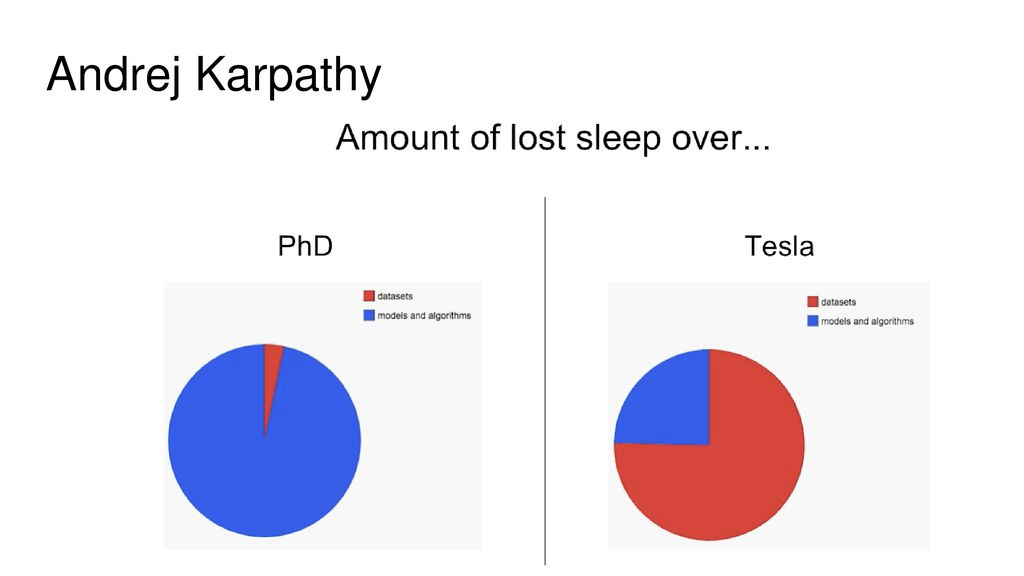
안드레이가 박사시절과 테슬라 시절에 잠을 빼앗긴 양을 표현한 차트입니다. 박사시절에는 모델과 알고리즘을 손봐야하는 일이 많았지만 이에 반해 실무에서는 데이터를 손봐야하는 일이 많아졌다고 한다.
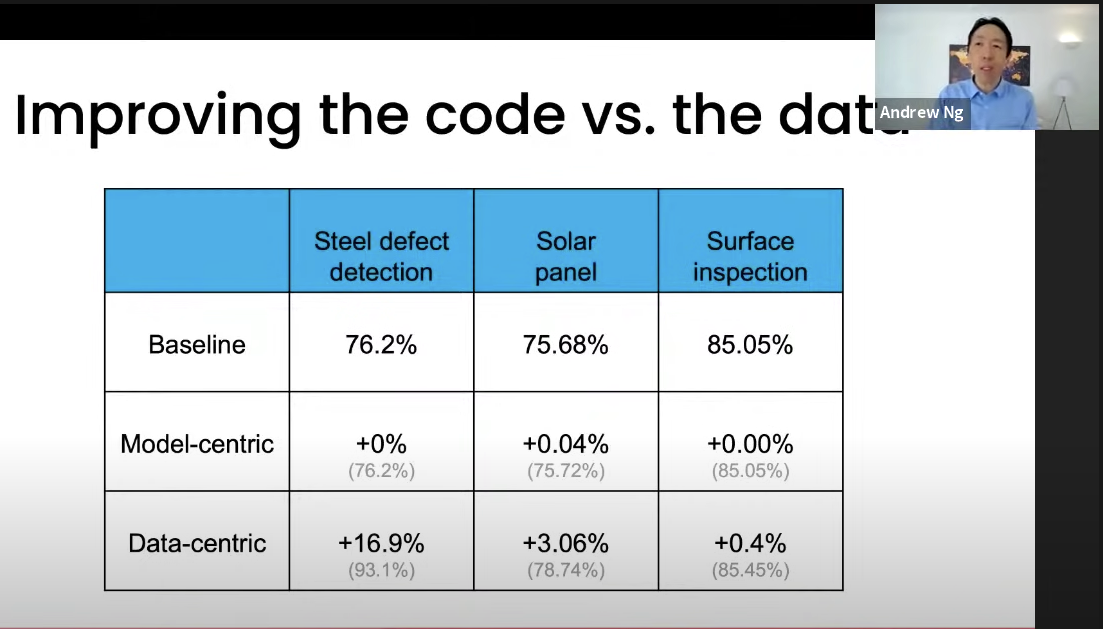
데이터 품질을 올리면 어떤 효과를 볼 수 있는지 나타낸 이미지로 model로 성능을 증진시키는 것 보다 더 많은 증진을 이뤄낸 것을 볼 수 있다.
이에 앤드류 응 교수님은 기존의 model centric competition이 아닌 data centric comeptition을 계최하였다.
Data handling of Tesla
데이터를 활용하여 극적인 성능으로 머신러닝 서비스를 제공하고 있는 기업으로 테슬라가 있다고 생각한다. 그렇다면 테슬라에서는 어떤 방법으로 Data centric ML service를 제공하는지 알아보자
-
bicycle object detection

(figure 1.) 서비스 제공 이전 테슬라의 데이터 샘플

(figure 2.)데이터 샘플 라벨링 결과물

(figure 3.)서비스 중 발생한 데이터 추론 결과
일반적인 상황의 데이터들은 (figure 1.)과 같았을 것이고 데이터 라벨링 또한 (figure 2.)과 같이 진행했을 것이다. 하지만 만약 (figure 3.)과 같은 데이터가 들어오게 된다면 어떻게 될까?? 자율주행 차량의 알고리즘은 서로 다른 객체로 인식하여 차량 앞에는 자전거가 있어 급정거 혹은 브레이크 이상작동으로 서비스의 품질이 떨어져 이를 해결하기 위해 fleet learning을 고안해냈다.
-
fleet learning
 (figure 4.) 서비스 중에 발생하는 데이터
(figure 4.) 서비스 중에 발생하는 데이터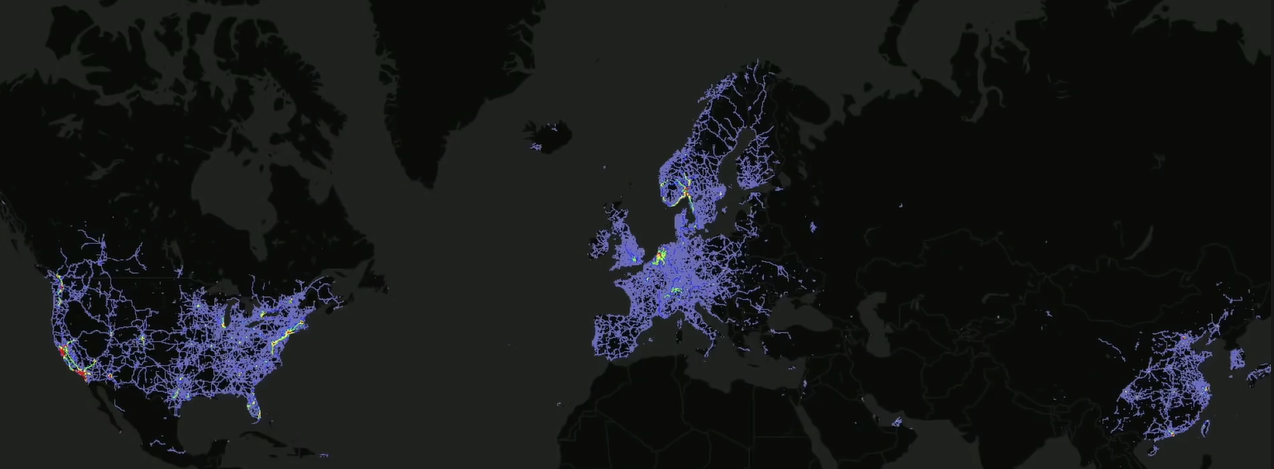 (figure 5.) 넓은 영역에서 데이터가 발생
(figure 5.) 넓은 영역에서 데이터가 발생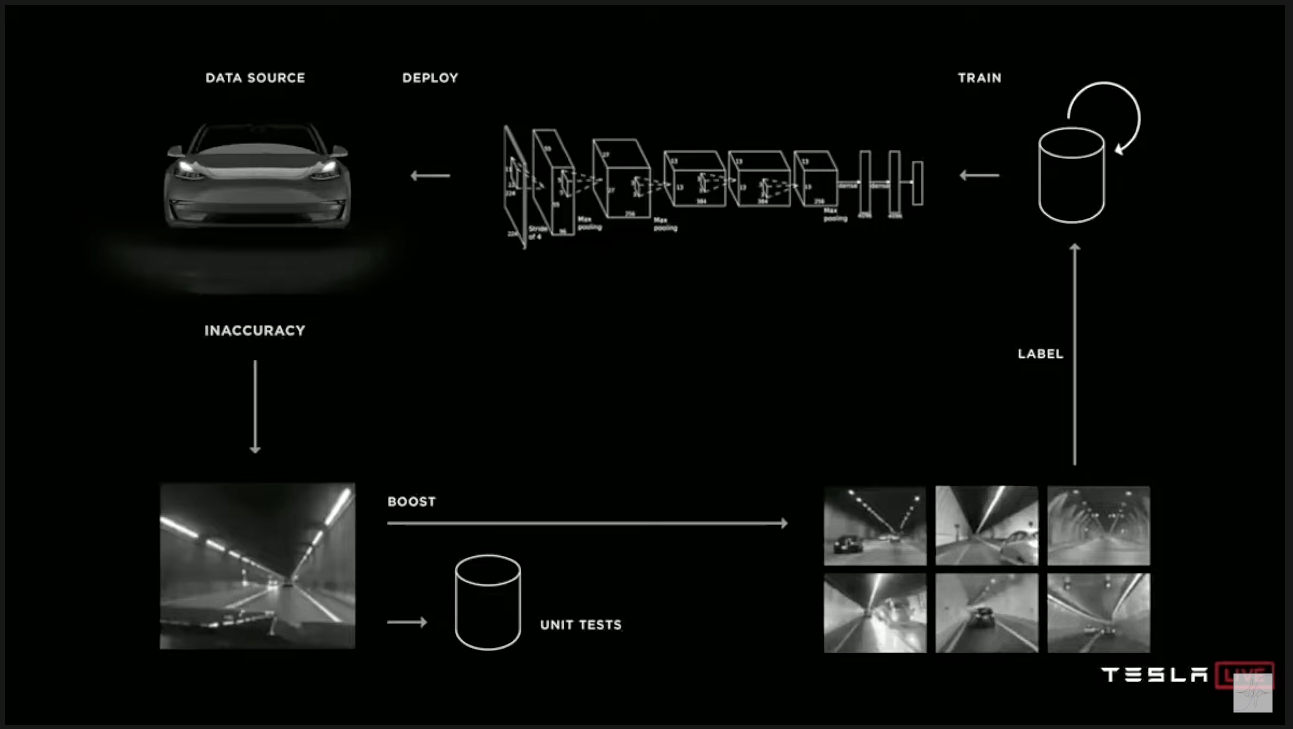 (figure 6.) fleet learning architecture
(figure 6.) fleet learning architecture테슬라는 자전거로 의해 발생하는 브레이크 오작동을 해결하기 위해 실제 서비스중에 발생하는 데이터를 수집하여 관리하여 이를 해결하였다.
fleet learning에 대해서 간단하게 알아보자면 아래와 같은 순서로 작동한다.(figure 6.)
- Data source(테슬라 사용자들의 차량들을 지칭)에서 부정확한 결과를 trigger로 전달
- 예를 들면 자율주행 모드를 사용자가 껐다.
- unit test로 실제 찾고자하는 경우의 데이터인지 판단
- unit test를 예를 들자면 위와 같이 자전거와 차량을 같은 객체라고 인식하지 않는 경우를 차량의 bounding box와 자전거의 bounding box가 서로 overlap되어 있는 상황(필자의 추측)
- 찾고자하는 경우인 데이터라고 하면 Boost를 통해 사용자에게 데이터 사용허가를 받아 데이터 셋을 수집 및 라벨링을 진행
- 추가된 데이터셋을 활용하여 다시 재학습
- 재학습된 모델을 Data source에 deploy
Fleet learning으로 생성되는 데이터는 Large Dataset(figure 5.), Varied dataset(figure 4.), Real dataset(figure 4.) 특징이 있어 서비스에 적합한 데이터셋을 얻을 수 있다.
- Large dataset
- Varied dataset
- Real dataset
- Data source(테슬라 사용자들의 차량들을 지칭)에서 부정확한 결과를 trigger로 전달
Reference
How AI Powers Self-Driving Tesla with Elon Musk and Andrej Karpathy
A Chat with Andrew on MLOps: From Model-centric to Data-centric AI
Closing Thought
ML system 도입을 위해 필요한 것은? (Software 2.0)
- computing
- code + algorithm = model
- Data
- (필자가 중요하게 생각하는 것)
- Issue tracking
- data drift
- model uncertainty
필자의 궁금증
-
과연 MLOps는 ML로 무언가를 만드는 사람들이라면 모두 필요한 것인가?? (MLOps is all you need??)
기업에서 MLOps 도입을 위해서는 전사적 협조가 필요해 보인다. 그리하여 작은 비용으로 쉽게 적용할 수 있는 것은 아니라고 보인다.
모두가 MLOps를 도입해야하는 것이냐고 생각해보면 그런것 같지는 않은 것 같다. 이를 분류할 수 있는 기준은 ML 모델이 얼마나 자주 기업에서 제공하는 서비스에 관여하냐에 따라 나눠질 것 같다. 조금 더 쉽게 표현하자면 ML 모델이 반복적으로 inference를 하냐 하지않냐에 따라 분류될 수 있을 것 같다.
-
decision cost는??
ML 서비스를 안정적으로 배포하고 유지하려면 많은 비용들이 발생할 것으로 보인다. 그로 인해 기업에서는 ML 서비스로 도입하였을 때 얻을 수 있는 가치와 불안정성에 의한 Cost는 계산이 필요해 보인다.
어떠한 Task에 어떤 Decision을 내리냐에 따라서 부과되는 cost는 매우 다를 것이라고 생각된다. 얼마나 가치 있는 일을 혹은 반복적인 일인지에 따라서 얻을 수 있는 가치가 평가가 필요하며 잘못된 Decision으로 발생하는 비용는 ML 서비스 기획 부터 운용관리 때까지 지속적으로 평가해야할 것으로 보여 ML 모델에 대한 모니터링이 필요해 보인다.