AI challenge solution
AI challenge solution
상수관로 누수감지 및 분류문제

과제 설명
✔ 상수관로 진동 센서 데이터로 누수 유형을 분류하는 문제
추진배경
✔ 환경부에 따르면 전국 수도관의 13%가 30년 이상 된 노후관로이며 적수 등 상수도 품질 저하의 주요 원인임
✔ 현재 누수 확인 및 유수율 관리는 누수탐사 전문가의 투입을 통해 이루어져 누수 감지 및 분류 자동화를 통해 시간과 비용을 절감할 수 있음
활용 서비스
✔ 센서 기반 누수 자동 탐지 솔루션
✔ 수돗물 품질 관리
데이터 설명
Input
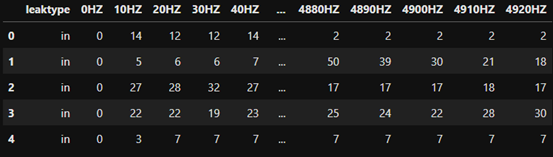
상수관로 진동 센서 데이터 (수치)
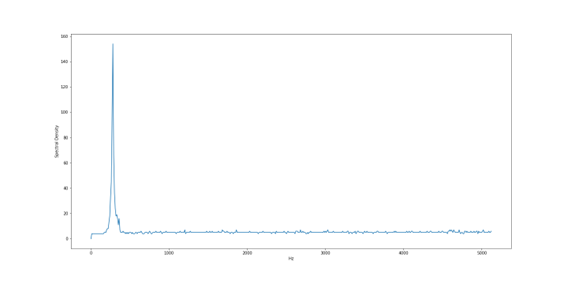
- 센서 출력값 데이터에 Fourier Transform을 적용하여 계산한 주파수 별 Spectral Density 값
Output
누수 구분 클래스
Class 종류
옥외누수(out), 옥내누수(in), 정상(normal), 전기/기계음(noise), 환경음(other)
Solution
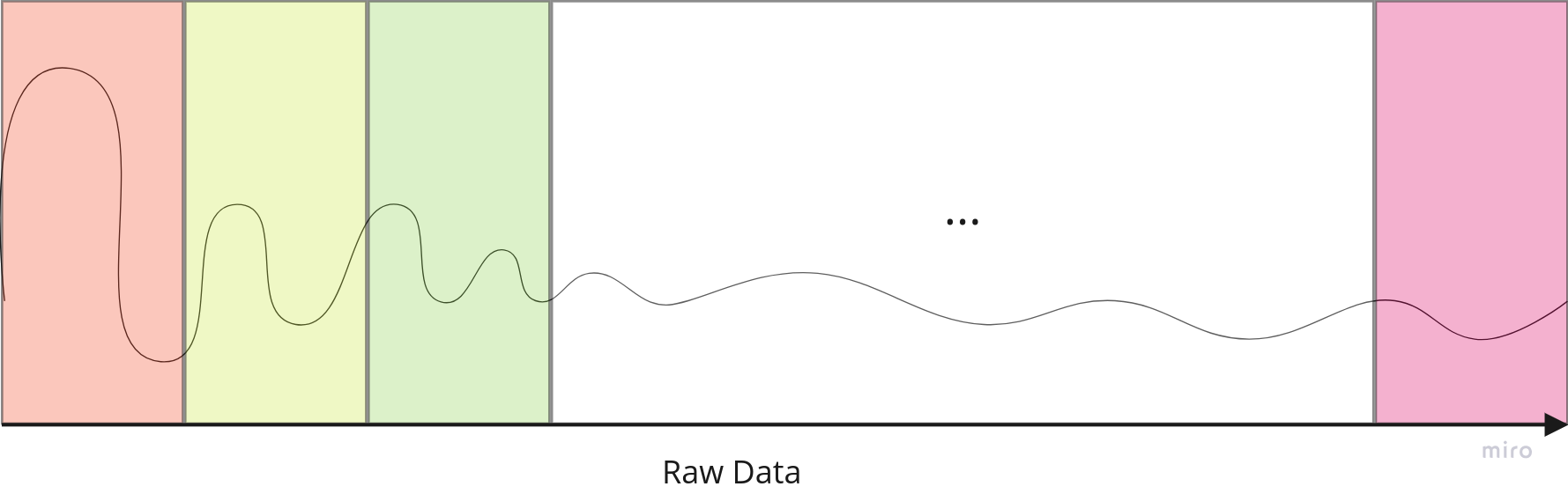
제공되는 데이터의 유형이 raw data를 fft data로 변환 되어 있어 시간정보가 사라지고 HZ의 density 정보가 제공되어 시계열 데이터로 보는 것이 아니라 1D 데이터라고 이해하여 분석을 진행하였다.
Multi-modal DL architecture
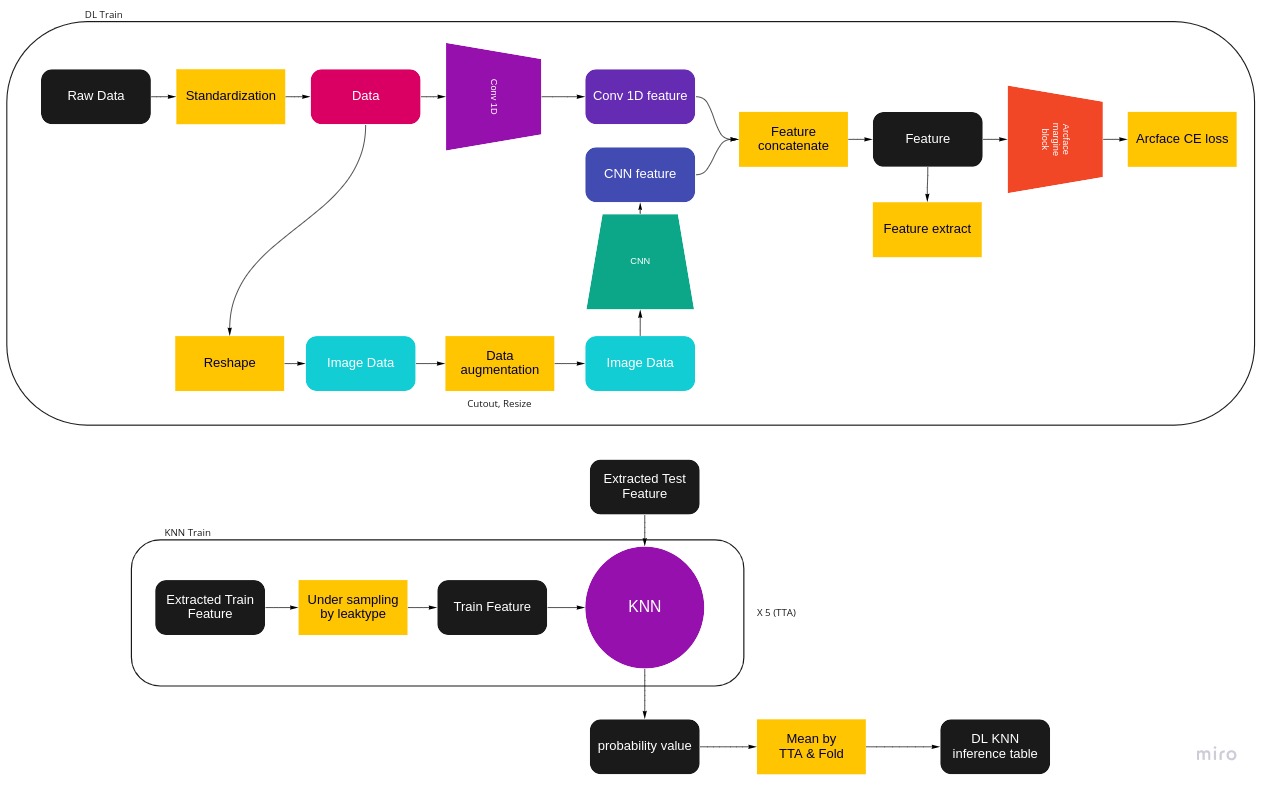
DL feature extract Network
DL - CNN Network
-
이전 버전
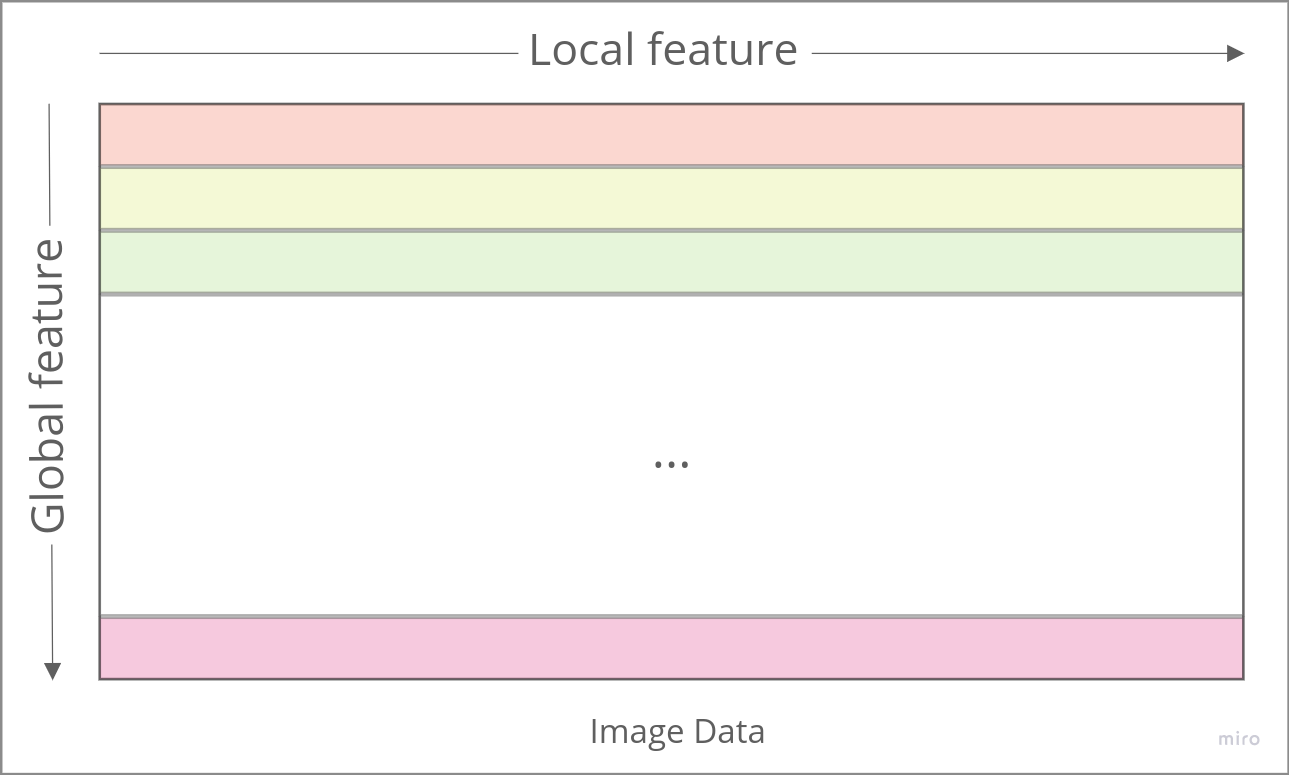
feature 정보를 reshape을 통해 2D data로 변환하여 W(Width) 방향으로 정보가 특정 사이즈 만큼의 local한 정보가 취합되고 W 방향으로 종합되는 정보가 H(Height) 방향으로도 종합되어 local한 정보와 global하게 종합되어 Local한 feature와 Global한 정보가 함께 종합되는 것을 기대할 수 있다.
-
원본 데이터를 reshape을 통하여 2D Image 데이터로 변환하여 width 방향으로는 local한 정보를 height 방향으로는 global한 정보를 추출할 수 있게 데이터를 가공 변환한 Image 데이터를 활용하여 ImageNet pre-trained CNN 모델을 활용하여 Transfer learning을 시행하여 분류에 활용할 수 있는 feature를 생성하였다.
-
train data의 imbalance 인하여 over-fit의 문제점이 있어 data augmentation을 적용
- 특정 data 정보가 없더라도 feature를 생성할 수 있도록 Cutout Data augmentation을 도입하여 이를 해결하였다.
DL - Conv 1D Network( 1 X 513 filter )
Conv 1D를 활용하여 data의 Global feature를 생성
우리가 사용한 Conv1D는 앞서 설명한 CNN 보다 Global feature를 추출할 수 있도록 유도하였다.
일반적으로 사용하는 Conv1D는 데이터를 filter size 만큼 순차적으로 읽어 feature를 생성하지만 우리의 Conv1D는 filter size를 Input size와 같아 한번에 모든 feature를 읽어 보다 더 global 한 정보를 추출할 수 있을 것으로 유도하였다.
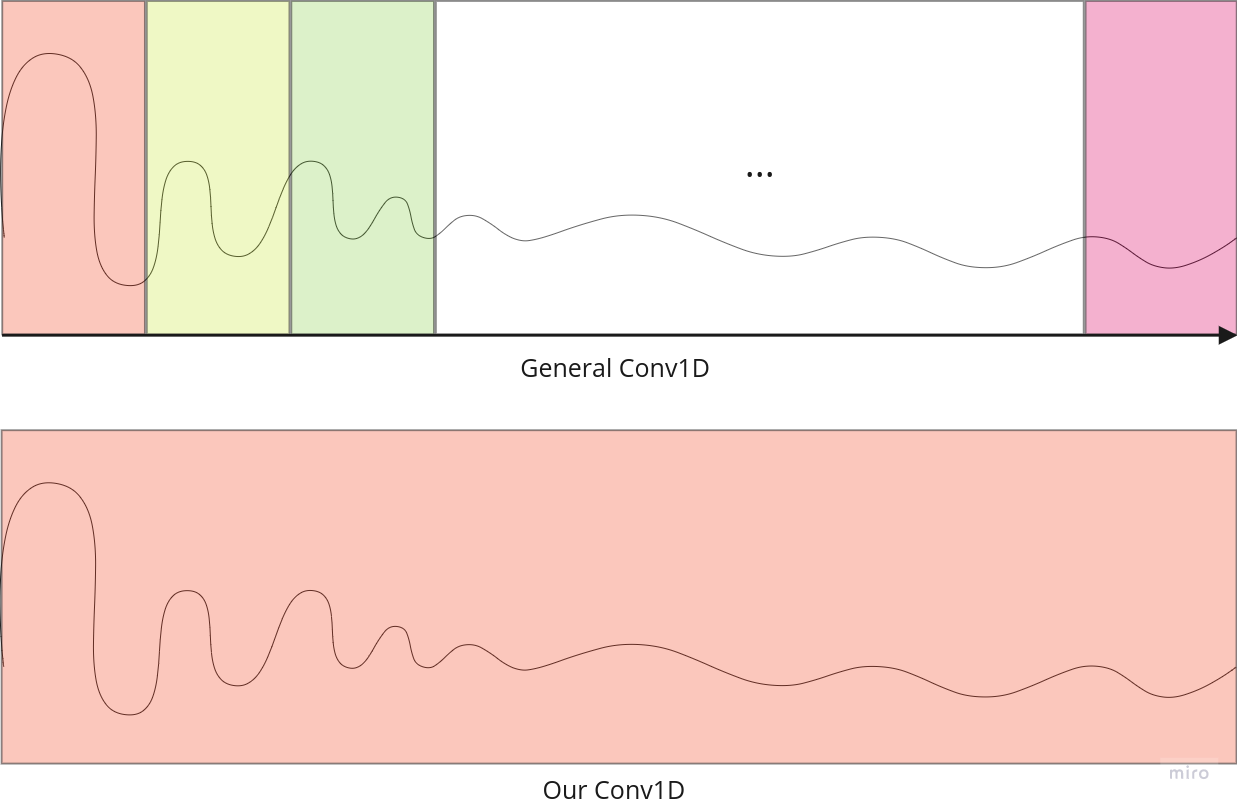
(총 2개 layer를 사용하여 activation function으로 ReLu를 사용)
Arcface margin with KNN(K-Nearest Neighbor)
Arcface margin
제공 받은 데이터는 data imbalance로 f1 macro score를 계산하는 것에 있어 leak type 중 in, out에 대한 성능이 좋지 않았다. 이를 해결하기 위해서 search 기반 알고리즘을 사용하였다. Arcface margin은 image retrieval에서 SOTA 방법으로 소개되었지만 few-shot learning으로 성능이 실험으로 확인되어 사용하였다.
Arcface margin의 역할은 data들이 각 leak type 별로 모이도록 학습하는 방법으로 (network로 생성되는 feature와 사용하는 weight parameter를 L2-normalize 후 서로 matrix multiplication하여 cosine similarity를 Cross Entropy로 loss function을 활용하게되면 feature들이 leak type 별로 모이게 된다.)
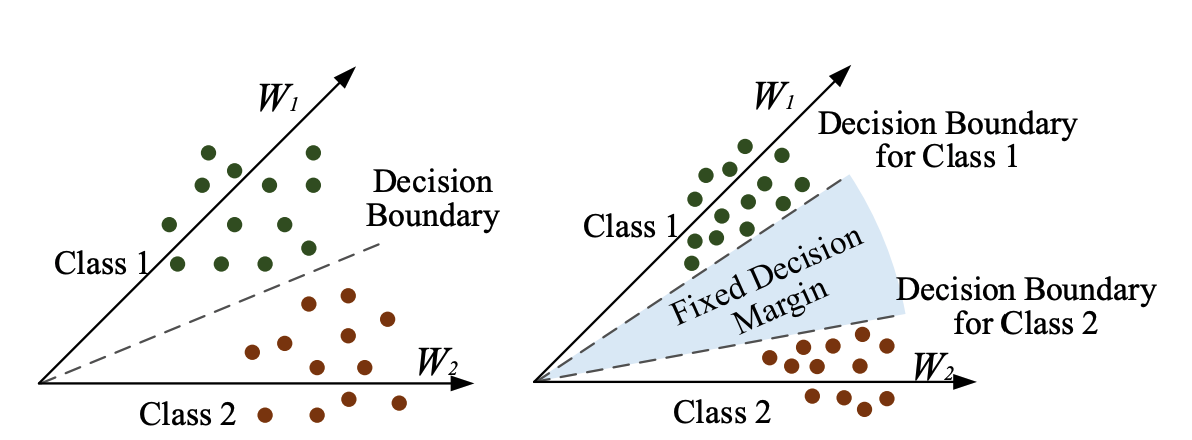
ArcFace: Additive Angular Margin Loss for Deep Face Recognition
KNN(K-Nearest Neighbor)
Arcface로 leak type 별로 모이게 된 feature들을 활용하여 KNN 알고리즘을 활용하여 test의 leak type을 예측한다. KNN 알고리즘은 distance base로 작동하기 때문에 train data의 imbalance로 인하여 성능 차이가 있어 가장 작은 in - out leak type 기준으로 1800개 데이터만 활용하여 train data를 정의하였다. 이를 다회 수행하여 bagging과 비슷한 역할을 할 수 있게 유도하였다.
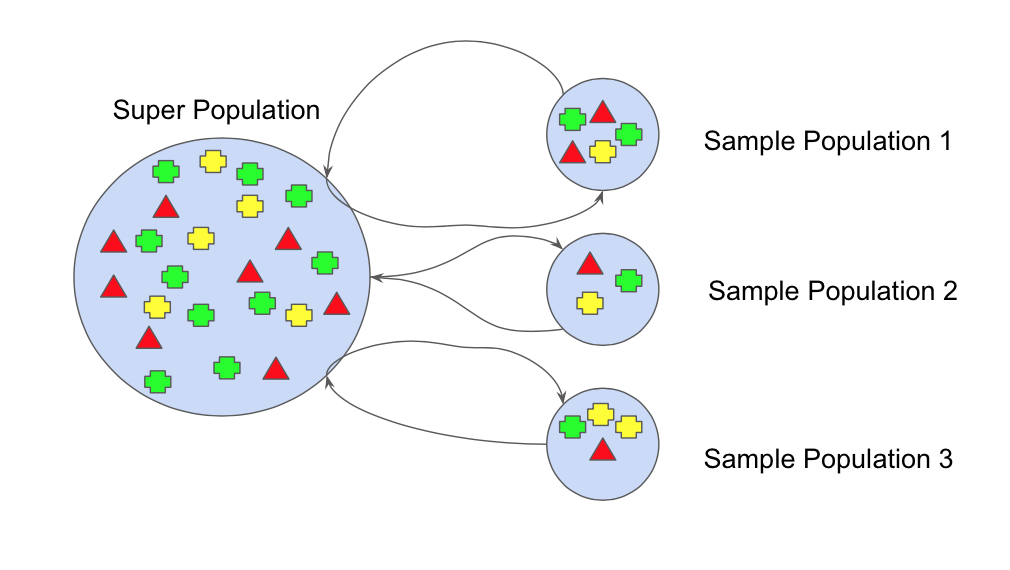
Under sampling
ML - KNN based LightGBM
Data imbalance에 대하여 상대적으로 적은 class에 weight를 부여하여 tree기반 모델을 개선하였지만, 옥내누수와 옥외누수 예측에 한계가 있었다. 한편, 거리기반 모델이 해당 class들에 대해 tree기반 모델보다 더 나은 예측 성능을 보였기 때문에 거리기반 모델을 적극적으로 활용하고자 하였다.
- Method(방법론)
- 데이터마다 가장 가까운 train data 5 건을 가져와 옥외누수, 옥내누수의 분포를 Feature로 반영
- LightGBM 모델에 Class weight를 부여하여 옥내누수, 옥외누수에 대한 예측 성능 보완 - **효과**
- feature 추가로 성능향상을 기대하기 어려운 거리기반 모델의 한계를 보완
- tree 기반 모델의 낮은 성능을 보완
- 다양한 관점에서 데이터를 분석
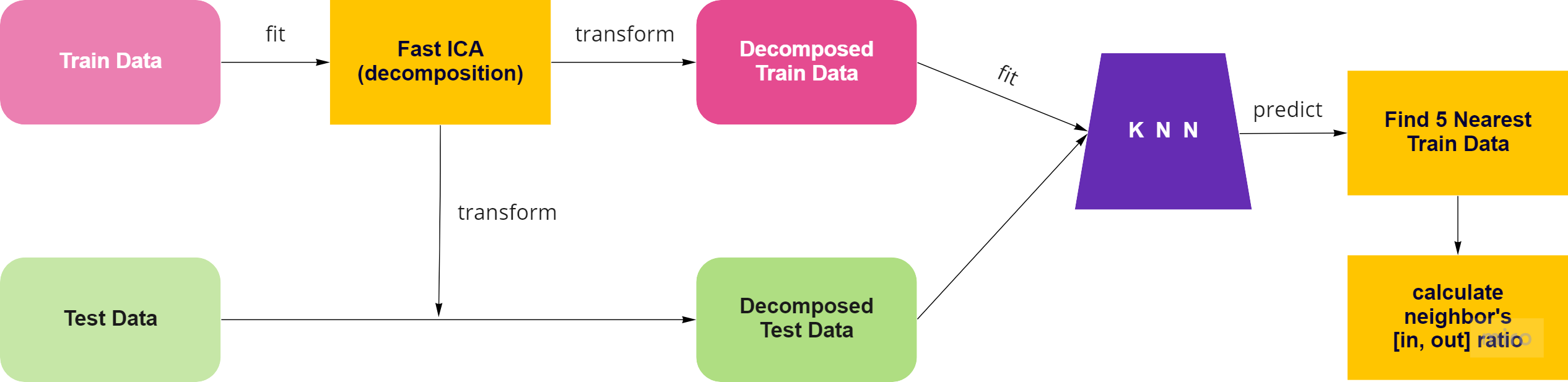
ML - Feature Engineering for LightGBM
같은 HZ라도 데이터마다 가지는 의미와 scale도 다르기 때문에, 푸리에 변환된 513개의 feature만으로 경계를 나누는 tree 모델은 효과를 보기 어려웠다. 이를 해결하기 위해 0HZ부터 5120HZ까지의 흐름을 나타낼 수 있는 변수를 추가하였다.
- Method(방법론)
- 원본 데이터의 0HZ부터 5120HZ 까지 feature를 Decomposition 기법인 Truncated SVD, ICA를 통해 축소하여 하나의 feature에서 가지는 정보량이 원본 데이터보다 크게 하였다.
-
김승일, “진동 데이터의 시간영역 특징 추출에 기반한 고장 분류 모델” 을 참고하여 신호의 실효치를 나타내는 RMS와 impulse factor를 추가하였다.

-
일정 window step마다 HZ간 통계치를 반영하였다. (ex. 0HZ~360HZ간 분산 등)
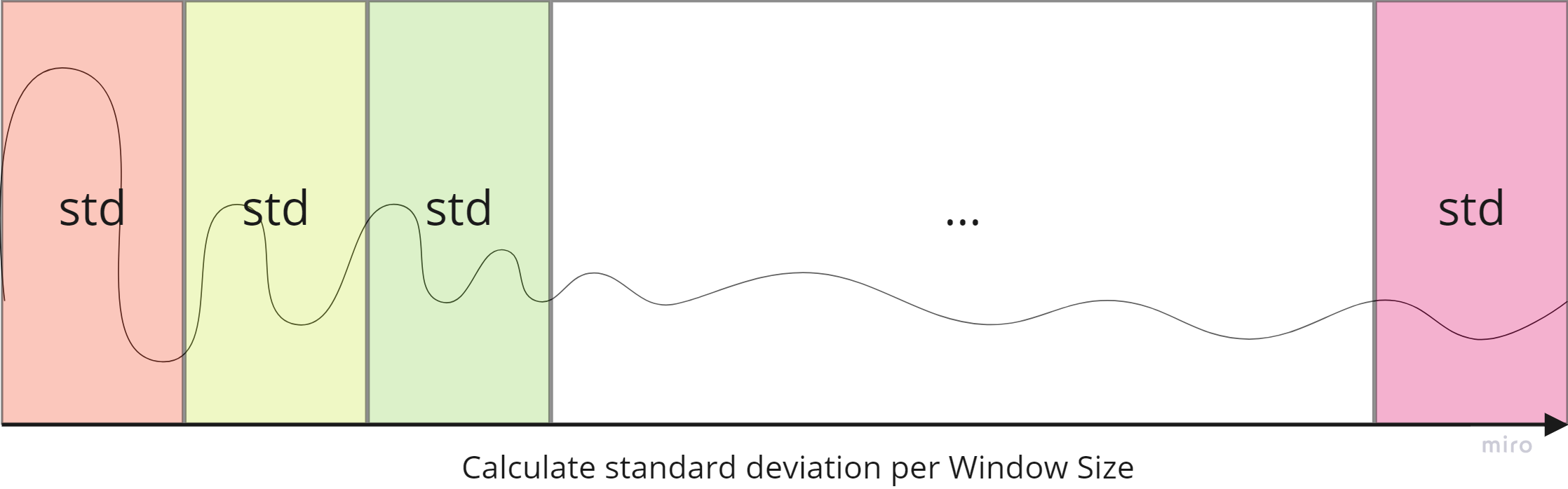
ML - Feature selection
Permutation feature importance를 계산하여 학습을 방해하는 60개의 feature를 제거하였다.
(permutation feature importance 그림)
Feature importance를 보았을 때, 0HZ부터 5120HZ까지의 흐름을 나타낼 수 있는 변수를 추가하는 방법이 효과적임을 볼 수 있다.
Ensemble
DL과 ML Model은 서로 이질적인 Model이기 때문에 Ensemble을 통해 높은 예측 성능이 나올 것으로 기대하였다. 또한, Ensemble을 통해 over-fitting의 발생을 방지를 목적으로 활용하였다.
DL의 결과와 ML의 결과를 Weighted soft voting을 통해 Ensemble을 진행하였다. (DL : ML = 6 : 4)
Post-process
train dataset에서의 imbalance 문제로 인하여 모델이 옥외누수, 옥내누수에 대한 성능이 낮아(옥외누수, 옥내누수 대신 다른 class로 예측하는 경향이 있었음) 이를 조절할 필요
옥외누수, 옥내누수에 대해서 특정 값 보다 높은 경우 해당 leak type으로 의사결정을 내리고 남은 데이터에 대해서 decision하였다. 두 leak type이 모두 threshold를 넘는 경우는 확률이 높은 class로 decision을 하였다.
Result
경진대회 결과
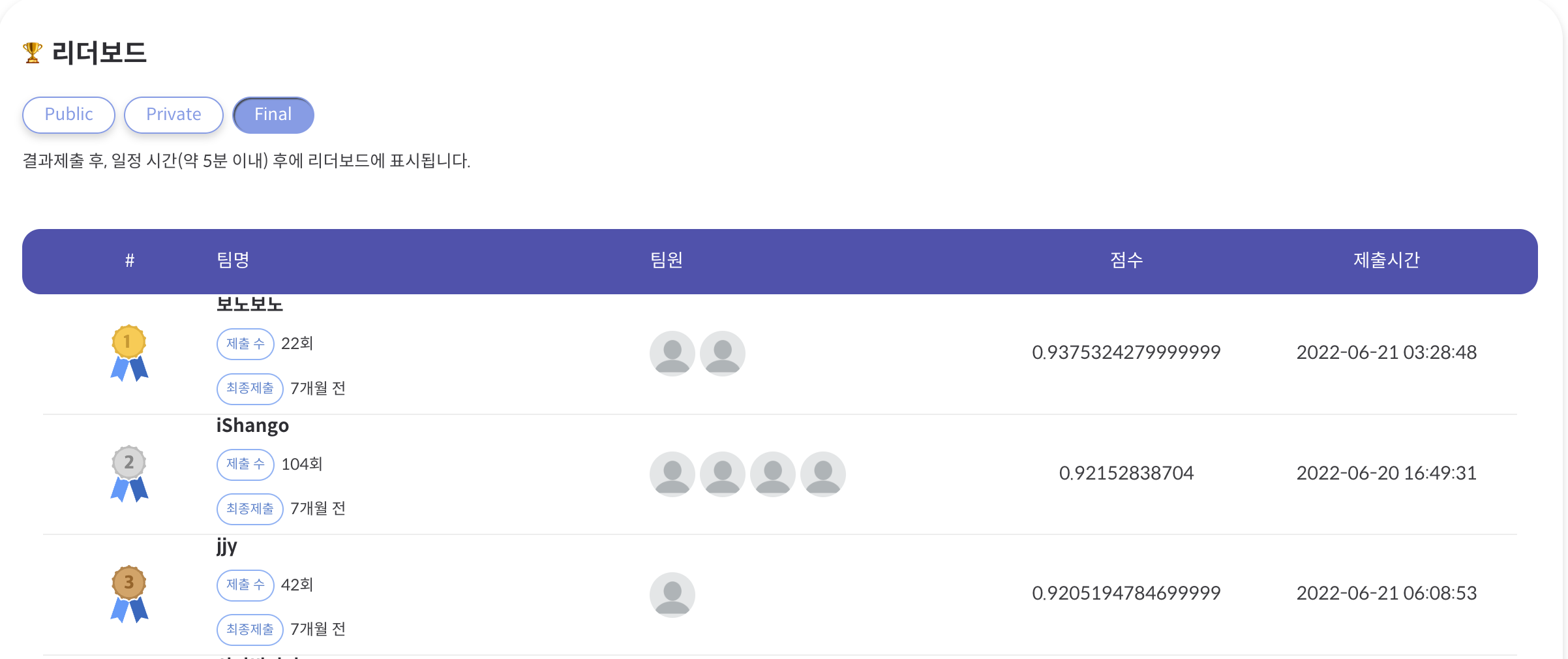
사업 결과